What I learned from mining researcher questions
I decided to get into text mining. Considering that I have basic programming skills, and I want to do some text mining for academic purposes, plus I’ve already looked at more than 80 tools researchers use…
How difficult can it be? I only need to find a question, some text, and pick a good enough tool.
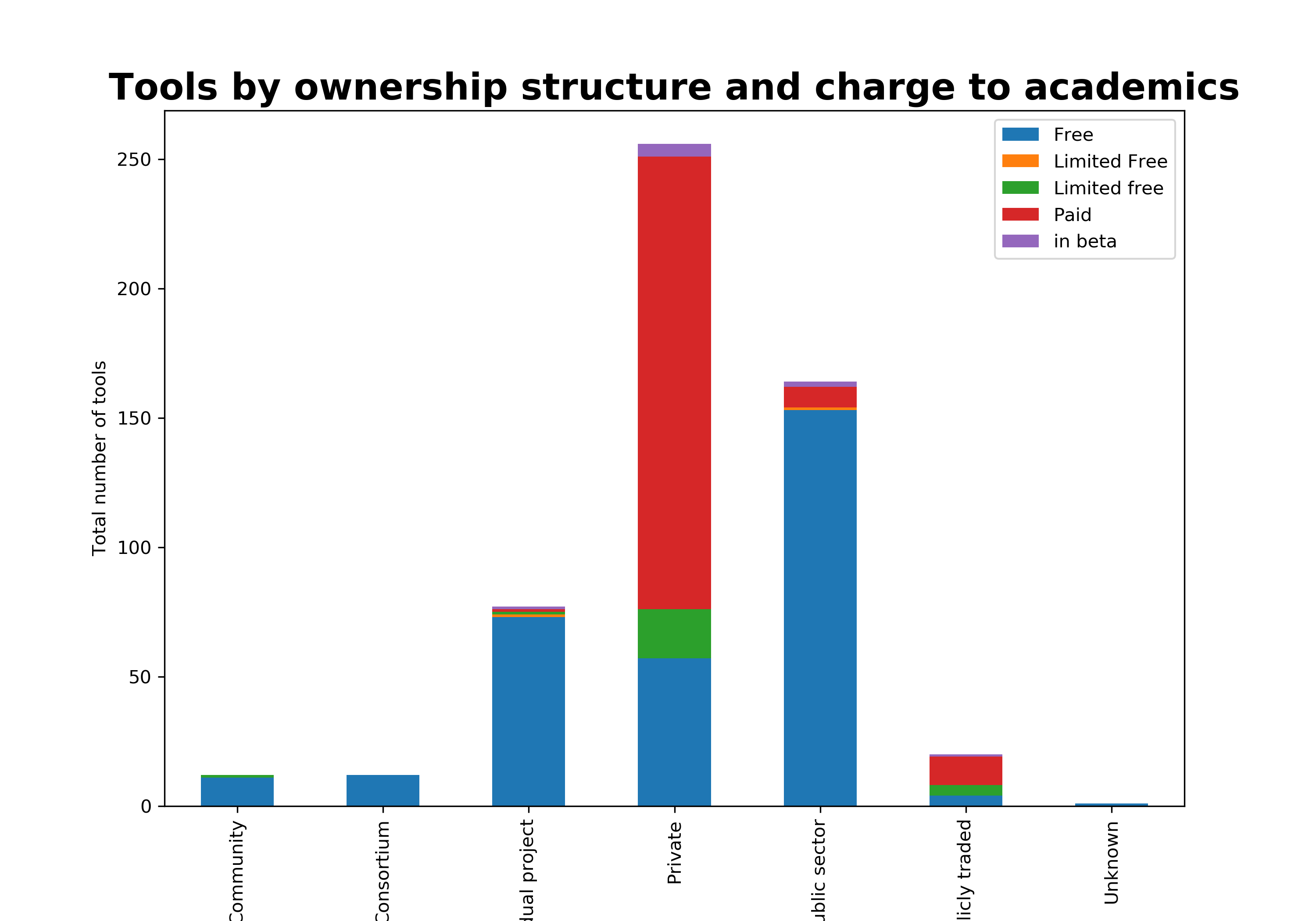
My natural inclination is to do some research on research, and text mining could help me scale this up. I picked the researchgate discussion forum for my analysis, and my question: what types of questions researchers ask most commonly.
My idea for a method…
collect the questions posted to researchgate over a few months, then use Orange Text and Data Mining (no coding skills needed) to cluster the corpus and see which clusters have the most questions.
Collecting and cleaning the data:
- I set up a daily scraper with import.io, that would crawl my personal research gate account for “Questions we think you can answer”. Now, of course, these are tailored for my ‘skills’, so I would expect questions in the entrepreneurship/intrapreneurship/innovation/business/technology/strategy/research methods space. I am also hoping the list will be biased towards social sciences and tools in the social sciences, as these were the type of questions I’d already answered on the platform.
- After 100 days of imports, I aggregated the data to obtain 5324 instances (i.e. rows, each row contains a question), which translated into 654 when removing duplicates.
The analysis:
- I chose to mine my corpus with Orange in order to make progress quickly. Given my basic coding skills, a no-code app seemed like the perfect option. I uploaded my corpus and applied some preprocessing steps. I knew I had to do this, because academics told me that’s the most boring bit of the process. Then followed about 3 hours of playing around:
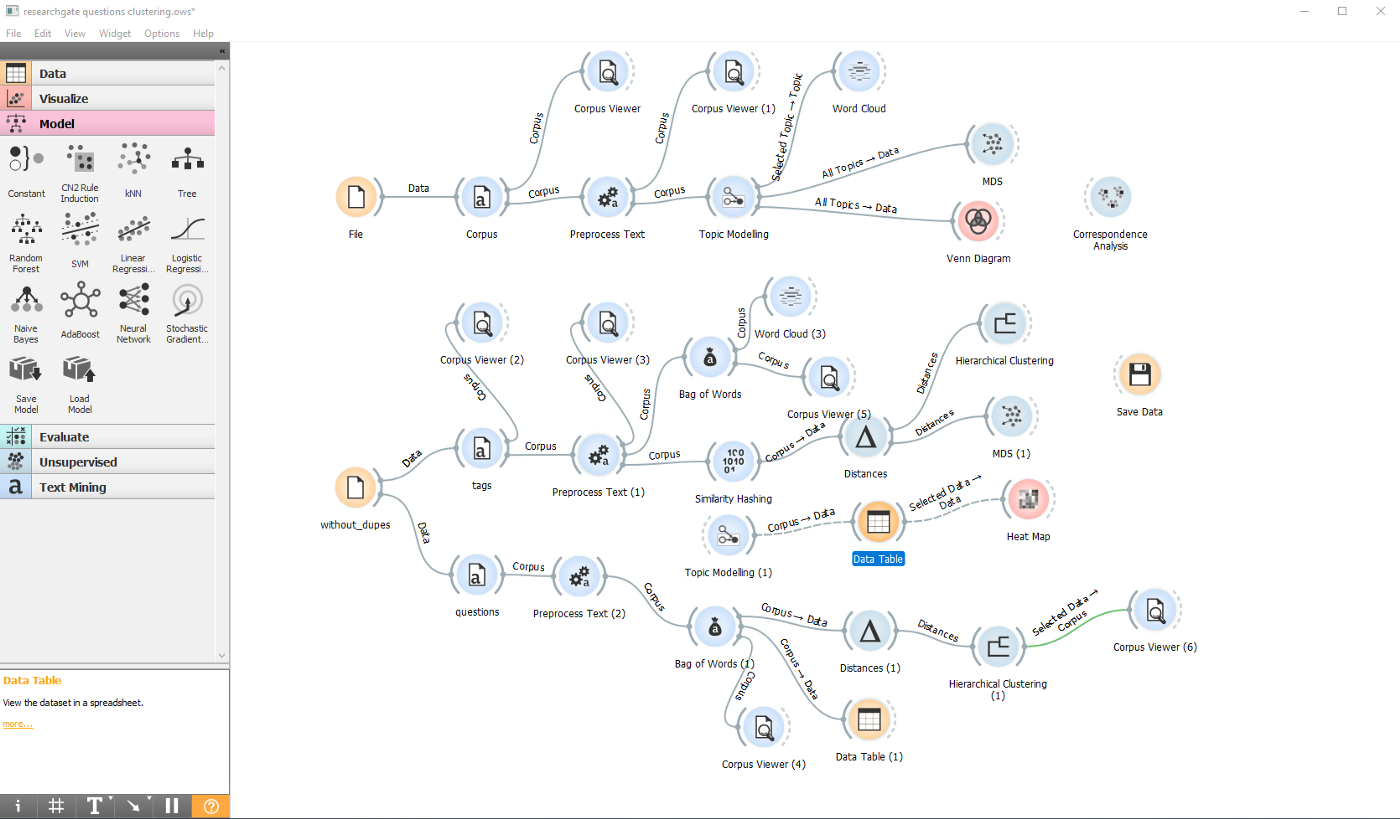
- I finally got somewhere. Best feeling ever. I ignored a few of the fields I scraped, thinking they would be useful, such as the number of reads and the action. That left me with just the title of the discussion or question, a short description (which is not always the full descriptive text, but a good first paragraph at least), and the tags inserted by the user. From the 654 documents (or individual and not duplicated questions scraped over 100 days from my research gate feed), Orange processed 6145 words, and since I chose uni and bigrams, that meant - 4781 tokens. I applied bag-of-words to convert my corpus into numbers (aka vectors of word counts). Other ways to word-embed should also be possible (I noticed an option for adding your own python script, so should be easy to do word2vec, though unsure about any of the transformers).
Ideally, my next step would be to do some clustering to get a sense of the most common topics.
But first, to give you an idea of the corpus, here’s a word cloud. As I expected, the majority of the questions I get contain words like innovation, business, management, entrepreneurship… Those were my self-attributed skills.

At this point, I realize (again) that my document classification may not have the useful results I was hoping for, i.e. I will not be able to correctly infer the most common questions. For that I will need a different data set, one that is not tailored for me, but a rather more ‘random’ sample. For now, I have to make do and will go ahead with the analysis, to learn more about Orange and my current corpus.
- I am finally ready to cluster the 654 questions. In order to do that, I use a step that measures the (cosine) distances between the documents or rows in my case. Since I applied the most simple word-to-numbers transformation (bag-of-words) in the previous step, the distances that Orange computes are a reflection of the presence or absence and frequency of all words in each row. Once I have these distances, I can apply hierarchical clustering, and I picked a depth of 10 (I don’t have a robust reason for it, open to discuss alternatives).
Having reflected a bit more about the simplicity of my analysis so far, I would expect questions on completely different topics to be closer together and clustered within the same group if they look similar. For example, questions that start in the same way and have multiple (not very important) words that repeat, like ‘what is the best way to do ….’ or ‘what is the difference between …’ or ‘how do I..’ will probably be closer, even if they ask about another topic, i.e. the keywords are different.
And yay! this is exactly what happens. a first glance scrolling through the clusters I see this:
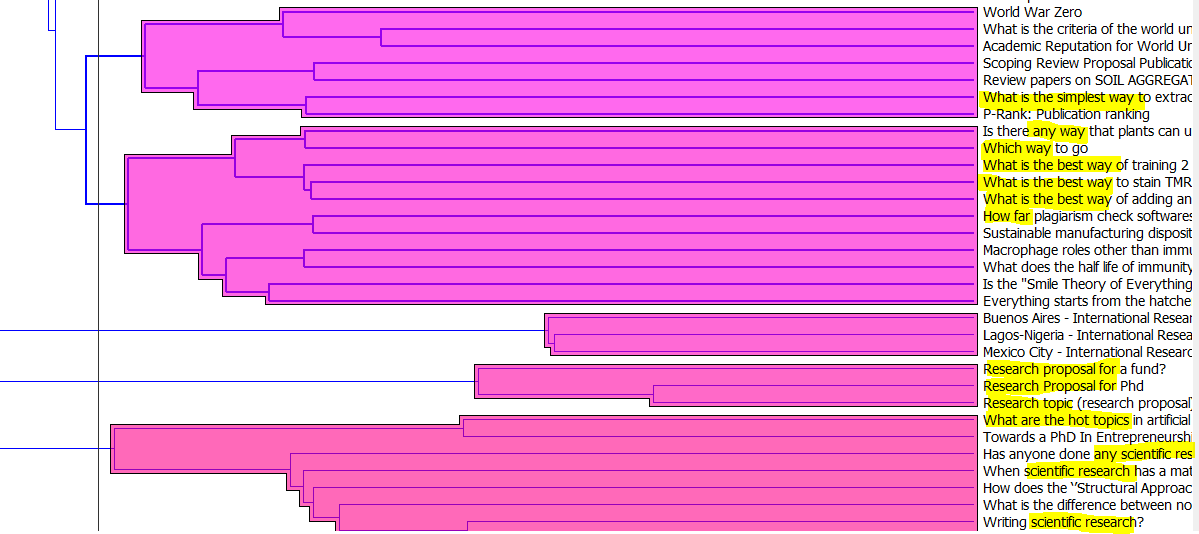
This is still useful though, because I could potentially cluster question by the type of help the researcher needs, rather than the content or discipline. How would I do that… welcome comments!
Final workflow
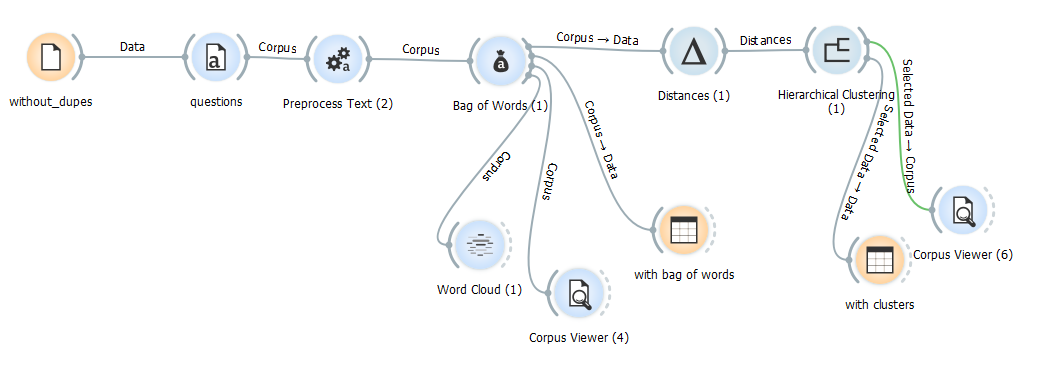
I was able to identify 68 different clusters with anywhere from 3 to about 50 questions in each, some make more sense than others. I would need to follow up with a more qualitative approach to really understand what’s going on. This short workflow is just the start of my analysis and, as many social science researchers would say, could help sort through the corpus, but not very likely to provide publishable results. Thoughts and questions
> Take-away 1: Scraping was so unbelievably easy!
Scraping has definitely gotten easier, and you don’t need to know how to set up complex crawlers. As long as you know which websites you want to scrape, you can easily set these up with import.io or other services like this. It’s easy because you can visually change the things that you want to collect, and the scraper sets it all up for you in csv or other structured formats. For me, this meant that there was almost no cleaning I needed to do because I selected exactly the bits of the page I wanted scraped, no more no less.
+helps to be in the UK: copyright exception for text mining means I can scrape and analyse content for non-commercial purposes.
> Take-away 2: A no-code platform doesn’t mean you don’t need any coding skills. In fact, you cannot do much if you don’t know at least how to construct a the workflow from a developer’s perspective.
Orange was quite useful. And whilst I did not spend time learning/improving my python scripting skills, I still needed to spend time to understand how a script would have been built. The workflow in Orange followed, what I believe is, a proper coder’s workflow. This is both good and bad. It’s good, because now I only need to learn the actual code/commands, as I already understand the sequence. It’s bad because it creates a little slump in the process, takes time to figure out and is not intuitive for the non-coder.
> Take-away 3: It’s so beautiful.
For my next mini-text-mining project, I am going to explore the questions and discussions where academics are asking for help in quantitative and computational social science.
What else should I do with this type of corpus? Please add in the comments, and if you used Orange or another tool, I am very curious about your workflows!